We’re doing it the Linux way this time: clean, efficient, and just a bit different. Let’s dive in.
UPDATE [2025/07/04]: The original NDK_ROOT and NDKROOT environment variables values used during the video shoot were misconfigured. That has now been corrected.
Building Unreal Engine 5.6 from the GitHub Source Code
Alright… I’m back.
Yes, I know—I vanished for a while. But just like the upcoming Unreal Engine 5.6 release, I’ve been quietly cooking in the shadows. And now… we’re both making a comeback.
Today’s tutorial is all about how to build Unreal Engine 5.6 from source—on Windows. That’s right, 5.6 isn’t officially out yet, but we’re not waiting around. If you’re impatient like me—or just curious to see what Epic’s brewing before the rest of the world—this video is for you.
Now, some of you patient folks out there might be thinking:
“Why bother? Can’t I just wait for the release?”
Fair question. But here’s the deal—I work for a company that publishes Unreal Engine plugins on the Fab Store. And they want their plugin ready on day zero when the new engine drops. The catch? Epic only allows you to submit plugins once the final version is officially released. So to stay ahead of the curve, we grab the source early, build it, test it, and make sure everything works before the launch day.
And hey, if you’re a Linux user—don’t worry—I’ve got a separate video coming soon. Just not today. Because building on Linux is like dating in your forties… not complicated, exactly—just different.
We’ll be diving into more Unreal Engine 5.6 goodness over the coming months, so buckle up, hit that subscribe button, and let’s get nerdy.
Posted on November 25, 2024
11 minutes
Mamadou Babaei
WebRTC IP Leak Demonstration using Rust and JavaScript
Deep in the vast jungle of the internet, an elusive predator lies in wait: the WebRTC IP leak. This invisible hunter slithers through the dense digital undergrowth, silent and unseen, ready to strike its next target. The IP addresses of its unsuspecting victims are exposed in an instant. But its danger isn’t merely technical; if you’re a political activist in a repressive regime, leaking your IP could jeopardize your very life. Today, we embark on an expedition to track this hidden predator, uncover its secrets, and learn how to protect ourselves before it strikes.
Posted on November 10, 2021
9 minutes
Mamadou Babaei
I recently purchased a second-hand HP Proliant ML350p Gen8 in order to be used as a home server and to my disappointment realized I won’t be able to disable the hardware RAID that comes with this model, at least at first glance. Well, there is a way to do that, which is supported by HP themselves. And, this is how to do it the easy way!
But, before we proceed any further, you might ask why do I need to disable the hardware RAID? The answer is because I need to install ZFS. There is already plenty of documentation why installing ZFS on a hardware RAID is a terrible idea. Thus, I won’t go over that since it’s not the focus of this article.
Again, before we go any further there’s a catch you should know about. If you’d enable HBA-mode, the server won’t be able to boot from any disk connected in HBA mode to the controller! You should consider this before converting to HBA mode. In case you need to perform a FreeBSD/Linux root on ZFS installation through this controller there are two solutions:
1. Installing in hardware RAID mode, but making each disk a RAID-0 array consisting of only one disk. For example, if you’ve got 8 disks, you’ll end up with 8RAID-0 arrays. Then you’d perform a ZFS installation and your operating system boots as expected. Though this is not recommended and if you’d proceed with this approach, it renders the rest of this post useless.
2. HP Proliant ML350p provides an SD-Card slot, which can be used to install a full system, which is not recommended due to the wear and tear effect of SDCards with each write-operation on them. In addition to that, this storage type is costly and slow. For example, a SanDisk SDXC Extreme Pro 256GB, which provides a write speed of 90MB/s and read speed of 170MB/s, costs around €99,99 where I live. With today’s standards, this is not fast at all or even good enough, especially on a server. I was also able to find a Sandisk CF Express Extreme Pro 512GB type B, with a write speed of 800MB/s and a read speed of 1500MB/s. It only costs €629,-, which costs an arm and leg to buy!
So, then! What’s the solution one might ask? We are going to install only /boot partition on the internal SD Card. Note, that placing only a bootloader such as GRUB, rEFInd or other similar tools won’t work as they won’t be able to see the boot drive anyway! So, the only solution is to put the boot partition on the SDCard. This way, the system only reads it one time at boot and it does not even have to be an expensive SD-Card.
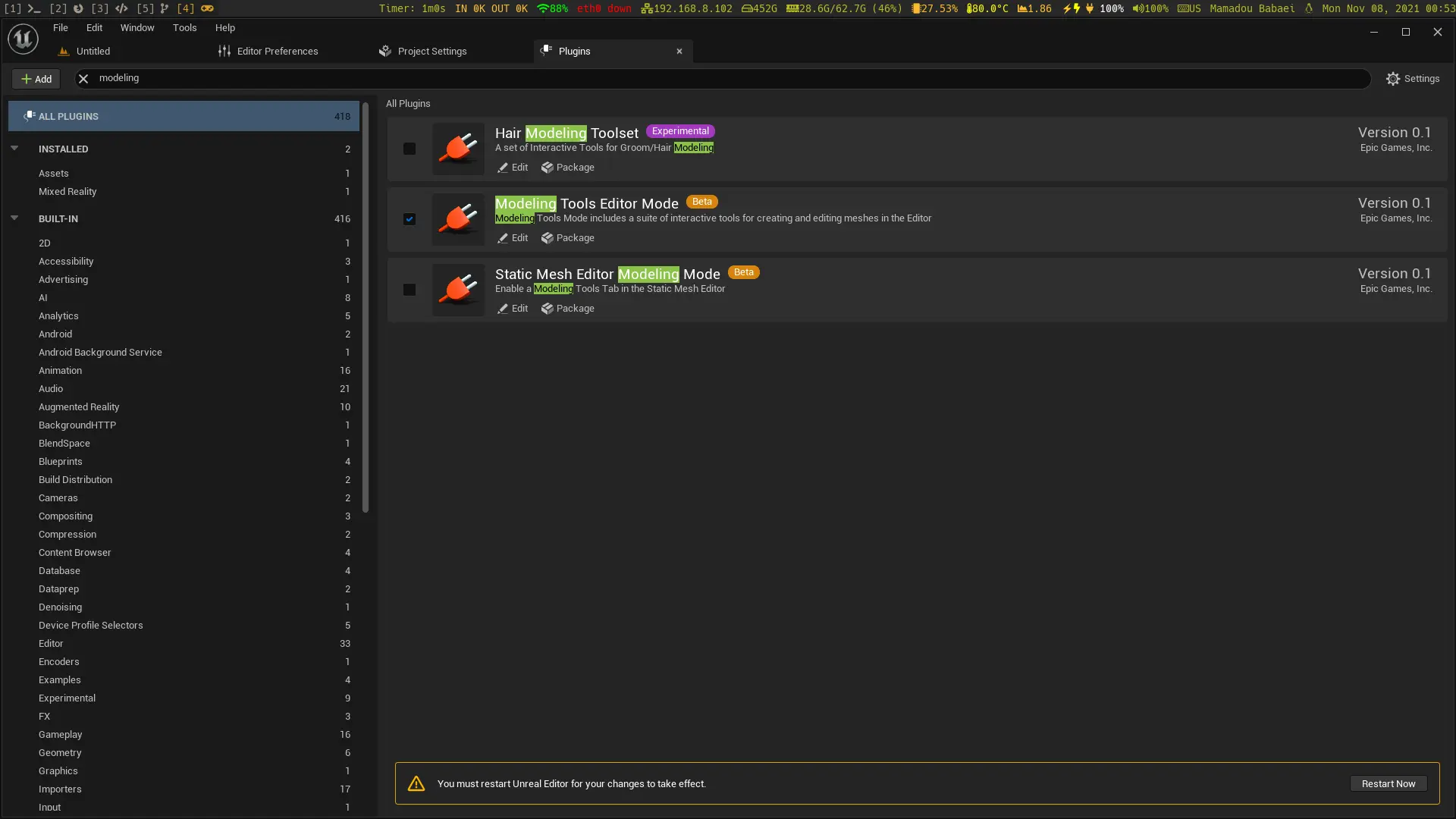
I’ve been trying to enable and make use of UE5’s Modeling Tools Editor Mode Plugin inside the editor built from ue5-main and 5.0 and struggled to some extent. According to Epic Games, this should suffice:
If you are starting up a new project, the modeling mode plugin may need to be turned on. From the Plugins window, enable the Modeling Tools Editor Mode Plugin and restart Unreal Engine.
So, I did enable the plugin from inside the editor:
To no avail and I was never able to find it inside the UE5 editor:
Unreal Engine Modeling Tools Editor Mode plugin not showing up after being enabled
Despite that, I was able to figure out what’s wrong. Here’s how I fixed it on Linux and it’s an easy fix. It probably works on macOS, too. Though I have no idea why Epic Games has disabled it on non-Windows platforms in spite of the fact that it works just fine.
Host Unreal Engine 4 projects on Microsoft Azure DevOPS with unlimited cost free Git LFS quota
UPDATE 1 [2021/07/25]: It seems that Git LFS is able to resume your pushes after a network failure. At least it’s like that on Microsoft Azure DevOPS. So, it should be totally redundant to divide huge commits into smaller ones. How have I noticed this? Today, I pushed a huge single commit (around 53GBs) and it failed at 39GB due to a connection error without me noticing it for some time. A few hours later, when I made another attempt by issuing the push command again, it picked up and resumed the push at 39GB, which was really exciting.
UPDATE 2 [2021/07/25]: After pushing the repository to Azure DevOPS, if you find your self stuck in git pull without doing anything, the following command will fix the consecutive pulls:
UPDATE 3 [2021/07/28]: I’ve noticed due to the fact that the files modification times affect how Rsync and Git work by default, my approach in writing the original script was totally wrong, which in turn caused a bug where on each update it committed all tracked files over again causing huge bloat in the repository, despite the fact that the content of the files was unchanged. Thus, it led me to completely rewrite the script. Hopefully, the new script has been extensively tested with two repositories/projects and works as expected. In addition to that, the script now shows progress for every step, which is a nice addition in order to keep you informed and give an estimation of the time it is going to take to get the job done. And, last but not least, I have edited and improved the blog post a bit.
UPDATE 4 [2021/08/04]: Due to nested .gitignore files inside the Unreal Engine dependencies, I noticed tiny bits of dependencies for building UE4/UE5 on Microsoft Windows are not getting copied over to the repository. As a result, I fixed the script in order to also take care of that.
UPDATE 5 [2021/11/30]: Sometimes it’s possible that the amount of renamed Unreal Engine files surpass the Git’s optimal rename limit inside the Sync repository (the intermediary local git repository that we are going to use for syncing the engine source code with upstream):
warning: exhaustive rename detection was skipped due to too many files.
warning: you may want to set your diff.renameLimit variable to at least 13453 and retry the command.
So, you could set that to a really large number in order to keep track of file renames:
Note: You will get this warning only when the Git option diff.renames is set to true (default behavior). Likewise, the above settings does not have any effects when the copy/rename detection is turned off. Nonetheless, you can always check your settings with:
$ git config -l
UPDATE 6 [2021/12/18]: I’ve added a step regarding EngineAssociation in the project’s .uproject file, which I forgot to mention in the original post.
UPDATE 7 [2023/03/03]: In UE5 UE4Games.uprojectdirs file shas been renamed to Default.uprojectdirs. Though the syntax and the contents of the file has remained the same.
UPDATE 8 [2023/03/04]: After upgrading my project to Unreal Engin 5.1 despite the fact that I’ve already set the git configuration http.version to HTTP/1.1 as instructed in this article, despite the commit size of no bigger than 166.30 MB and the acceptable upload bandwidth I’ve got, I was getting HTTP 413 Request Entity Too Large error:
Enumerating objects: 190058, done.
Counting objects: 100% (164439/164439), done.
Delta compression using up to 16 threads
Compressing objects: 100% (113439/113439), done.
Writing objects: 100% (138834/138834), 166.30 MiB | 47.32 MiB/s, done.
Total 138834(delta 35613), reused 121343(delta 22206), pack-reused 0error: RPC failed; HTTP 413 curl 22 The requested URL returned error: 413send-pack: unexpected disconnect while reading sideband packet
fatal: the remote end hung up unexpectedly
Everything up-to-date
I tried every suggestion that I came across in order to debug and resolve the issue to no avail. Including enabling git verbose logging:
This attempt was futile as well, that made me revert back to https. Then I tried to push commit by commit since I had made a few commits using (5.1 which has been repeated twice in the following command, is the name of the new local branch intended to be pushed):
$ git rev-list --reverse 5.1 | ruby -ne 'i ||= 0; i += 1; puts $_ if i % 1 == 0' | xargs -I{} git push origin +{}:refs/heads/5.1 --no-verify
And sadly, the approach of pushing one commit at a time was frutiless as well :/
Thus, for the time being I’m stuck pushing the updated project from my Linux machine and pulling it from my Windows machine. I’ll do another updated once I’ve figured what’s going wrong.
UPDATE 9 [2023/03/04]: As an experiment, I did create a new organiation and a new repository inside it. Then prior to changing the origin URL, I fetched all LFS objects issuing:
¯\_(ツ)/¯ as unexpected as it seems, it worked! As you can see my actual Git objects without the LFS objects on this repository are in no way near the 10 GB size limit:_
UPDATE 10 [2023/03/05]: Yesterday, I removed a large redundant repository from the previous organization, in order to see if I could still push my updates and the error I am getting was not due to hitting some kind of ceiling limit. It didn’t work. I did also cleanup the limit hacks I’ve added to my ~/.gitconfig in UPDATE 8. Then, after successfully pushing to the new organization/repository, I’ve decided to revert back the URL section for the orgin inside my .git/config inside the local repository and try to push once more to the old repository and guess what? It worked! Weird Microsoft/Azure! Not sure what fixed the issue. It could be even I had to wait for Microsoft to clean up the repository’s space I’ve deleted if the organization size limit was the issue. Don’t really know.
Among the gamedev industry, it’s a well-known fact that Unreal Engine projects sizes have always been huge and a pain to manage properly. And it becomes more painful by the day as your project moves forward and grows in size. Some even keep the Engine source and its monstrous binary dependencies inside their source control management software. In case you are a AAA game development company or you are working for one, there’s probably some system in place with an unlimited quota to take care of that. But, for most of us indie devs, or individual hobbyists, it seems there are not lots of affordable options, especially that your team is scattered across the globe.
There are plenty of costly solutions to keep UE4 projects under source control; ranging from maintaining a local physical server or renting a VPS with plenty of space on the cloud, equipped with a self-hosted Git, SVN, or Perforce, to use cloud SCM providers such as GitHub, GitLab, BitBucket, or Perforce. Since I prefer cloud SCM providers and Git + Git LFS (which also supports file locking), let’s take a look at some popular ones such as GitHub and GitLab.
GitHub for one, provides data packs, but the free offering is far from enough for collaborative UE4 projects:
Every account using Git Large File Storage receives 1 GB of free storage and 1 GB a month of free bandwidth. If the bandwidth and storage quotas are not enough, you can choose to purchase an additional quota for Git LFS. Unused bandwidth doesn’t roll over month-to-month.
…
Additional storage and bandwidth is offered in a single data pack. One data pack costs $5 per month, and provides a monthly quota of 50 GB for bandwidth and 50 GB for storage. You can purchase as many data packs as you need. For example, if you need 150 GB of storage, you’d buy three data packs.
For GitLab, although the initial generous 10GB repository size is way beyond the 1GB repository size offer by GitHub, the LFS pricing is insanely high:
Additional repository storage for a namespace (group or personal) is sold in annual subscriptions of $60 USD/year in increments of 10GB. This storage accounts for the size calculated from Repositories, which includes the git repository itself and any LFS objects.
When adding storage to an existing subscription, you will be charged the prorated amount for the remaining term of your subscription. (ex. If your subscription ends in 6 months and you buy storage, you will be charge for 6 months of the storage subscription, i.e. $30 USD)
Well, before this all get you disappointed, let’s hear the good news from the Microsoft Azure DevOPS team:
In uncommon circumstances, repositories may be larger than 10GB. For instance, the Windows repository is at least 300GB. For that reason, we do not have a hard block in place. If your repository grows beyond 10GB, consider using Git-LFS, Scalar, or Azure Artifacts to refactor your development artifacts.
Before we proceed any further, there are some catches to consider about Microsoft Azure DevOPS:
1. The maximum Git repository size is 10GB, which considering that we keep binary assets and huge files in LFS, is way beyond any project’s actual needs. For Git LFS it seems that Microsoft since at least 2015 has been providing unlimited free storage. For comparison, the engine source code for 4.27 is 1.4GB, which in turn when it’s getting committed to the git repo becomes less than 230MB:
2. The maximum push size is limited to 5GB at a time. The 5GB limit is only for files in the actual repository and it won’t affect LFS objects. Thus, there are no limits for LFS objects’ pushes. Despite that, if your internet connection is not stable, you could divide your files into multiple commits and push them separately. For example, the initial git dependencies for UE 4.27 is around 40GB spanned across ~70,000 files. Instead of committing and pushing a 40GB chunk all at once, one could divide that into multiple commits and push those commits one by one using the following command:
$ git rev-list --reverse master \
| ruby -ne 'i ||= 0; i += 1; puts $_ if i % 1 == 0'\
| xargs -I{} git push origin +{}:refs/heads/master
3. Sadly, at the moment Azure DevOPS does not support LFS over SSH. So, you are bound to git push/pull over https, which for some might be annoying. Especially, that it keeps asking for the https token 3 consecutive times on any push or pull!
Q: I’m using Git LFS with Azure DevOps Services and I get errors when pulling files tracked by Git LFS.
A: Azure DevOps Services currently doesn’t support LFS over SSH. Use HTTPS to connect to repos with Git LFS tracked files.
4. Last but not least, there is an issue with the Microsoft implementation of LFS, which rejects large LFS objects and spits out a bunch of HTTP 413 and 503 errors at the end of your git push. It happened to me when I was pushing 40GB of UE4 binary dependencies. The weird thing was I tried twice and both times it took a few good hours till the end of the push operation and based on measuring the bandwidth usage, the LFS upload size appeared to be more than the actual upload size. According to some answers on this GitHub issue and this Microsoft developer community question, it seems the solution is running the following command inside the root of your local repository, before any git pull/push operations:
$ git config http.version HTTP/1.1
Well, not only it did the trick and worked like a charm, but also the push time on the following git push dropped dramatically to 30 minutes for that hefty 40GB UE4 binary dependencies.
OK, after getting ourselves familiarized with all the limits, if you deem this solution a worthy one for managing UE4 projects along with the engine source in the same repository, in the rest of this blog post I’m going to share my experiences and a script to keep the engine updated with ease using a Git + LFS setup.
Posted on February 25, 2020
4 minutes
Mamadou Babaei
Well, anyone who has ever developed a C++ game or application with Gregorian to Jalali date conversion (or, vice versa) requirement is well aware of the hurdles of doing such a task. I, for one, have been maintaining my own cross-platform C++ library for almost two decades now, with occasional bugs coming up from time to time.
Recently, I have been playing with boost::locale (developed by Artyom Beilis and contributed to Boost project) a bit more in order to utilize it in a personal project called Barandazstorm, a home-grown social media analysis tool. Browsing the docs, I noticed the following example which does not even compile on my compiler:
boost::locale Gregorian to Hebrew date conversion example
1
2
3
4
5
6
7
8
9
10
11
12
13
usingnamespace boost::locale;
usingnamespace boost::locale::period;
generator gen;
// Create locales with Hebrew and Gregorian (default) calendars.
std::locale l_hebrew=gen("en_US.UTF-8@calendar=hebrew");
std::locale l_gregorian=gen("en_US.UTF-8");
// Create a Gregorian date from fields
date_time greg(year(2010) + february() + day(5),l_gregorian);
// Assign a time point taken from the Gregorian date to date_time with
// the Hebrew calendar
date_time heb(greg.time(),l_hebrew);
// Now we can query the year.
std::cout <<"Hebrew year is "<< heb / year << std::endl;
So, I tried to make a guess and replaced the en_US.UTF-8@calendar=hebrew part with en_US.UTF-8@calendar=jalali which didn’t work. But, on the second try replacing that with en_US.UTF-8@calendar=persian actually worked! Which is sheer delight; due to the fact that now I found a solution to convert dates between both calendars as efortless as techonologies such as .NET in C++:
Two-way Gregorian / Jalali date conversion using boost::locale
/**
* @file
* @author Mamadou Babaei <info@babaei.net>
* @version 0.1.0
*
* @section LICENSE
*
* (The MIT License)
*
* Copyright (c) 2020 Mamadou Babaei
*
* Permission is hereby granted, free of charge, to any person obtaining a copy
* of this software and associated documentation files (the "Software"), to deal
* in the Software without restriction, including without limitation the rights
* to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
* copies of the Software, and to permit persons to whom the Software is
* furnished to do so, subject to the following conditions:
*
* The above copyright notice and this permission notice shall be included in
* all copies or substantial portions of the Software.
*
* THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
* IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
* FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
* AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
* LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
* OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN
* THE SOFTWARE.
*
* @section DESCRIPTION
*
* Two-way Gregorian / Jalali date conversion using boost::locale example
*/#include<iomanip>#include<iostream>#include<cstdlib>#include<boost/locale.hpp>voidfrom_gregorian_to_jalali()
{
boost::locale::generator generator;
std::locale locale_gregorian = generator("en_US.UTF-8");
std::locale locale_jalali = generator("en_US.UTF-8@calendar=persian");
boost::locale::date_time gregorian(
boost::locale::period::year(2020)
+ boost::locale::period::february()
+ boost::locale::period::day(25),
locale_gregorian);
boost::locale::date_time jalali(gregorian.time(), locale_jalali);
std::cout <<"Persian date is "<< jalali / boost::locale::period::year()
<<"/"<< std::setfill('0') << std::setw(2)
<< (jalali / boost::locale::period::month()) +1<<"/"<< std::setfill('0') << std::setw(2)
<< jalali / boost::locale::period::day()
<<"."<< std::endl;
}
voidfrom_jalali_to_gregorian()
{
boost::locale::generator generator;
std::locale locale_gregorian = generator("en_US.UTF-8");
std::locale locale_jalali = generator("en_US.UTF-8@calendar=persian");
boost::locale::date_time jalali(
boost::locale::period::year(1398)
+ boost::locale::period::month(11)
+ boost::locale::period::day(06),
locale_jalali);
boost::locale::date_time gregorian(jalali.time(), locale_gregorian);
std::cout <<"Gregorian date is "<< gregorian / boost::locale::period::year()
<<"/"<< std::setfill('0') << std::setw(2)
<< (gregorian / boost::locale::period::month()) +1<<"/"<< std::setfill('0') << std::setw(2)
<< gregorian / boost::locale::period::day()
<<"."<< std::endl;
}
intmain()
{
from_gregorian_to_jalali();
from_jalali_to_gregorian();
return EXIT_SUCCESS;
}
On a side note, for the above code to work your boost::locale libraries has to be built with ICU support; otherwise boost::locale throws an exception. On most Linux or BSD distros this is the default when you install Boost libraries from your distro’s package manager. On Windows, it requires a bit of effort if you are trying to build Boost binaries yourself, which is another story for another time.
I did test the above code on FreeBSD, Linux, and Microsoft Windows, using MSVC, GCC, LLVM/Clang, and MinGW, and it’s working as expected on all of these platforms.
Posted on August 19, 2019
2 minutes
Mamadou Babaei
A few months back due to various changes in how Funtoo is being managed, I migrated back from Funtoo to Gentoo after almost a decade. After some time I realized my laptop randomly gets stuck on a blank screen and freezes just right before my login manager (SDDM) starts. I noticed the hard-disk LED is blinking and the system is actually not freezed and probably is working and stuck on something. Checking the system or Xorg logs did not reveal anything unusual.
I even posted my issue on the Gentoo Forums and when I thought the issue is gone I marked it as SOLVED (well, I don’t turn off this laptop or reboot too much). But, the problem came back and hunted me over again.
Finally, I decided to install JuiceSSH on my phone since I do not have access to another PC for the time being. When it did freeze, I did ssh into my Gentoo installation and noticed udevd’s CPU usage is at 100%. I looked up the forums to see if someone else having this issue or not. I cannot recall where on the forums I saw it, but it seems this was a known issue to some users with recent NVIDIA drivers and someone suggested blacklisting the NVIDIA drivers, so the kernel won’t load them at boot time as it is going to be loaded by X later on.
Well, I did the following changes in order to blacklist the NVIDIA modules, so the kernel won’t load them at boot itme:
And, viola! It has been a month without any issues so far. It did solve the issue for me, once and for all. Hope it helps someone with a similar issue until this bug is officially fixed.